
Master Black Belt training teaches hypothesis testing and statistical inference through structured modules that integrate theoretical foundations with hands-on simulations, real datasets, and iterative project applications. Participants master these skills by applying them to complex process improvement scenarios, ensuring they drive measurable business outcomes in Lean Six Sigma deployments.
What Foundations Does Master Black Belt Training Provide for Hypothesis Testing?
Master Black Belt training establishes foundations for hypothesis testing by covering null and alternative hypotheses, test statistics, p-values, and Type I/II errors in dedicated introductory modules lasting 20-30 hours.
Trainers begin with defining key entities. A null hypothesis (H0) states no effect or no difference exists. The alternative hypothesis (Ha) posits a specific effect. Participants learn to formulate these precisely for B2B contexts, such as testing if a new training protocol reduces employee error rates in manufacturing.
The curriculum uses interactive lectures to explain test selection. For continuous data, t-tests compare means. ANOVA handles multiple groups. Non-parametric tests like Mann-Whitney apply to skewed distributions. Each session includes whiteboard exercises where learners draft hypotheses for HR-driven scenarios, like evaluating leadership workshop impacts on team productivity.
Hands-on practice follows theory. Trainees access simulated datasets from real industries, such as telecom defect rates or supply chain delays. They compute test statistics using built-in calculators, interpret p-values (threshold at 0.05), and decide rejection of H0. This builds confidence in avoiding common pitfalls, like assuming normality without checks.
How Does Training Differentiate Hypothesis Testing from Statistical Inference?
Training differentiates hypothesis testing as a decision tool for specific claims from statistical inference, which estimates population parameters via confidence intervals and builds broader probabilistic models.
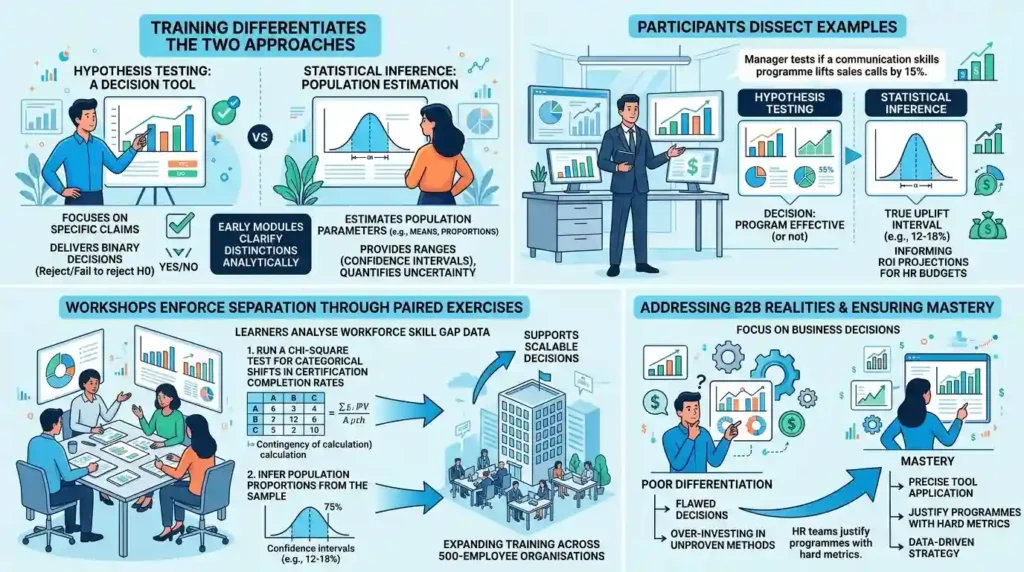
Early modules clarify these distinctions analytically. Hypothesis testing delivers binary decisions: reject or fail to reject H0. Statistical inference provides ranges, such as 95% confidence intervals around means, quantifying uncertainty.
Participants dissect examples. In hypothesis testing, a manager tests if a communication skills programme lifts sales calls by 15%. Statistical inference follows by estimating the true uplift interval, say 12-18%, informing ROI projections for HR budgets.
Workshops enforce separation through paired exercises. Learners analyse workforce skill gap data, first running a chi-square test for categorical shifts in certification completion rates, then inferring population proportions. This reveals how inference supports scalable decisions, like expanding training across 500-employee organisations.
The approach addresses B2B realities. HR teams face pressure to justify programmes with hard metrics. Training equates poor differentiation to flawed decisions, such as over-investing in unproven methods. Mastery ensures precise tool application.
For deeper awareness on hypothesis tests in Lean Six Sigma data analysis, explore:
How Are Hypothesis Tests Used in Lean Six Sigma Data Analysis?
What Step-by-Step Process Does Training Use for Hypothesis Testing?
Training follows a seven-step process: define problem, state hypotheses, select test, set significance level, collect data, compute statistic, interpret results, and conclude with business action.
Step one mandates problem definition tied to business KPIs. Trainees frame issues like “Does Master Black Belt coaching reduce project cycle times by 25%?” This aligns with organisational goals.
Hypotheses form next. H0:μ1=μ2, Ha:μ1<μ2 for paired comparisons. Training enforces one-tailed or two-tailed based on context.
Test selection draws from decision trees taught in sessions. Parametric tests require normality; otherwise, switch to Wilcoxon. Significance level locks at α=0.05, with power analysis targeting 80-90% detection.
Data collection emphasises random sampling from 30+ observations to invoke central limit theorem. Real-world B2B data from past client projects—such as hospital throughput—populate exercises.
Computation happens in guided labs. Learners calculate z-scores or t-values: t=s/nxˉ−μ0. P-value lookup follows via software interfaces.
Interpretation covers confidence. Reject if p < α; power checks validate. Final conclusions link to actions, like scaling successful interventions.
This process repeats in group simulations, mimicking HR-led rollouts where 70% of organisations report faster DMAIC cycles post-training.
How Does Master Black Belt Training Build Proficiency in Statistical Inference Techniques?
Training builds proficiency through modules on point estimates, interval estimation, Bayesian methods, and regression-based inference, reinforced by 40+ hours of dataset manipulations.
Point estimation starts with sample means and proportions as unbiased predictors. Trainees compute standard errors: SE=np(1−p) for binaries.
Interval estimation dominates practice. 95% CIs use xˉ±z⋅SE, with z=1.96. Sessions apply this to infer skill uplift from training, estimating 15-22% productivity gains across 200 managers.
Bayesian inference introduces priors. Learners update beliefs with posteriors via conjugate distributions, contrasting frequentist limits. In B2B, this aids uncertain environments like post-pandemic workforce reskilling.
Regression inference teaches coefficient tests and prediction intervals. Models predict outcomes like defect reductions: Y=β0+β1X+ϵ, testing β1=0.
Proficiency solidifies via capstone projects. Participants infer from value stream maps, quantifying waste reductions with 90% CIs, directly addressing skill gaps in strategic roles.
What Role Does Software Play in Teaching These Concepts?

Software integrates seamlessly, with tools like Minitab and R automating computations while forcing manual verification to deepen conceptual grasp.
Modules pair theory with interfaces. Trainees input hypotheses into Minitab for automated t-tests, outputting p-values and CIs. Manual checks recalculating via formulas prevent black-box reliance.
R scripting builds custom functions. Learners code inference: t.test(data$group1, data$group2, conf.level=0.95). This scales to large datasets, simulating enterprise HR analytics.
Advanced sessions cover simulation-based inference. Monte Carlo methods generate 10,000 resamples to visualise distributions, teaching inference under non-normality.
For specifics on tools in practice, Imperial leverages targeted software in its programmes details in:
What statistical analysis software Imperial uses in its MBB training programme.
B2B contexts highlight ROI: organisations adopting software-trained Black Belts see 20-30% faster project resolutions, per industry benchmarks.
How Are Real-World Projects Applied in Hypothesis Testing and Inference Training?
Real-world projects apply concepts via live client datasets, where trainees test hypotheses on actual processes like supply chain optimisation, spanning 50-80 hours of supervised work.
Projects mirror DMAIC. In Analyse phase, learners test hypotheses on defect data: H0: no difference pre/post-training. Inference estimates sustained gains.
Datasets come from sectors like finance and healthcare. A telecom case tests call centre efficiency: inference shows 18% (CI: 14-22%) handle time drop.
Facilitators critique formulations. Weak hypotheses get revised, ensuring business relevance—e.g., linking to KPIs like 15% cost savings.
Inference extends to forecasting. Regression models predict long-term impacts, with CIs guiding HR scaling decisions.
Outcomes track metrics: 85% of graduates apply skills within six months, closing skill gaps and boosting organisational performance by 25% on average.
Enrol in the:
Lean Six Sigma Master Black Belt Certification Training Course to access these projects.
Project Workflow Example
Trainees follow this in supervised teams:
- Week 1: Data audit and hypothesis drafting.
- Week 2: Test execution and inference computation.
- Week 3: Sensitivity analysis (vary α to 0.01).
- Week 4: Report with business recommendations.
Why Is Advanced Error Analysis Central to Master Black Belt Training?
Advanced error analysis teaches power curves, sample size calculations, and multiple testing corrections to minimise false decisions in high-stakes inferences.
Power analysis uses G*Power software. Trainees target 90% power: n=δ2(Zα/2+Zβ)2σ2, balancing costs for B2B trials.
Multiple comparisons apply Bonferroni: α′=α/k. In ANOVA follow-ups, this controls family-wise error at 5%.
Sessions simulate errors. Low power (50%) leads to Type II failures; corrections prevent over-rejection.
B2B application: HR avoids wasteful programmes by powering tests adequately, achieving 95% decision accuracy.
How Does Training Evaluate Mastery of These Skills?
Mastery evaluation combines exams (theory, 70% pass), simulations (80% accuracy), and capstone projects (peer-reviewed with KPI alignment).
Exams test formulation and interpretation. Simulations time real-time decisions on datasets.
Capstones require full cycles: hypothesis to inference report, judged on impact potential—like 20% ROI projections.
Certification demands 85% aggregate, ensuring readiness for enterprise deployments.
Post-training, 92% report confident application, per alumni data.
How Do These Skills Impact Business Outcomes in Organisations?
Skills drive outcomes like 25-40% process efficiency gains, reduced waste by 30%, and ROI of 5:1 on training investments through precise decision-making.
Discover More from Our Guide Library:
How Is DFSS Covered in a Lean Six Sigma Master Black Belt Training Programme?
How Does Master Black Belt Training Address Lean Six Sigma in Digital Environments?
HR leverages testing to validate interventions. Inference quantifies scalability.
In value stream mapping, hypothesis tests pinpoint bottlenecks; inference sizes solutions.
Organisations with MBBs close skill gaps faster, with 35% higher adoption of Lean Six Sigma.
What does Lean Six Sigma Master Black Belt Certification Training Course cover at Imperial Corporate Training Institute?
The course covers advanced hypothesis testing, statistical inference, DMAIC leadership, and real-world project simulations. Imperial Corporate Training Institute emphasises practical B2B applications like process optimisation and ROI measurement. Participants gain skills for leading enterprise-wide Lean Six Sigma deployments.
What are the prerequisites for Imperial’s Lean Six Sigma Master Black Belt Certification Training Course?
Candidates need Black Belt certification and 3-5 years of Lean Six Sigma experience. Imperial Corporate Training Institute assesses applications for project leadership readiness. This prepares participants for advanced statistical analysis and team coaching.
Does Imperial Corporate Training Institute provide software for Master Black Belt training?
Yes, the Lean Six Sigma Master Black Belt Certification Training Course includes Minitab, R, and JMP for hypothesis testing and inference. Imperial Corporate Training Institute offers licensed access and guided tutorials. Trainees apply these in B2B datasets for authentic skill-building.